
Market Intelligence
Market intelligence encompasses a wide range of insights, such as competitor activities, consumer trends, and emerging opportunities, that can inform strategic decision-making for businesses.
With the use of Graphlit and Azure AI, market intelligence can be automated - accelerating the time to insight. Ingesting data from public data sources - such as social media, podcasts, and websites - is a perfect starting point for building a knowledge base about businesses of interest.
Reddit can be a valuable source of information for research. Its vast array of user-generated content in the form of discussions, comments, and posts can provide real-time insights into consumer sentiment, emerging trends, and product feedback.
By monitoring relevant subreddits, you can gain access to unfiltered, authentic opinions and discussions that might not be as readily available through traditional market research methods.
For example, we can ingest data from r/ArtificialInteligence, and look for mentioned companies, topics and people, which provides insights on trends in AI.
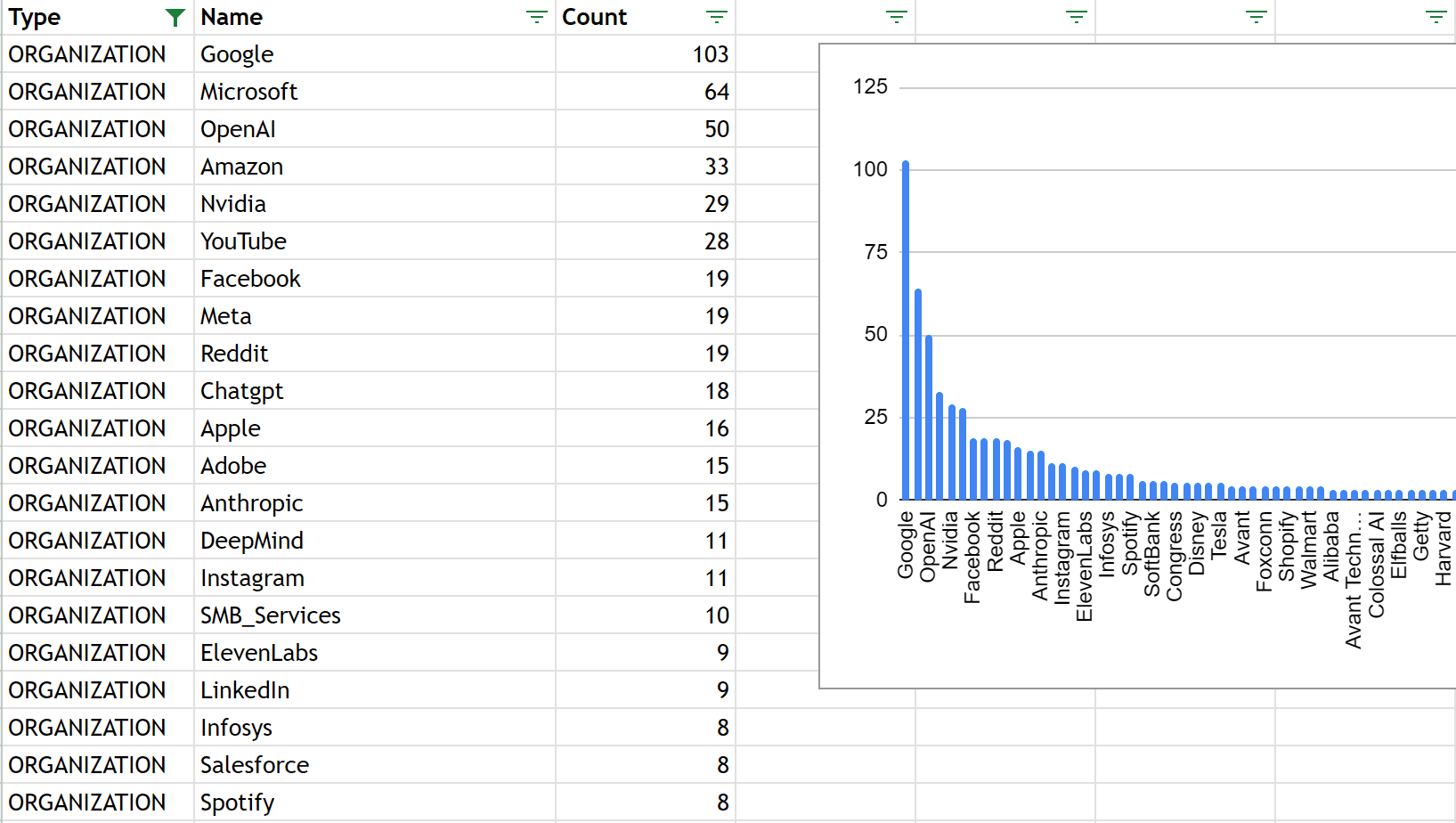
Most Mentioned Companies
Here is an example of the most mentioned companies from 1000 Reddit posts from r/ArtificialInteligence.

Not surprisingly, the top 5 mentioned companies are Google, Microsoft, OpenAI, Amazon, and Nvidia.
But for your market intelligence investigation, it may be interesting to see that Coca Cola was mentioned twice, in an AI subreddit.
This analysis can be done on any subreddit, which does not have to be technology or AI related.
Most Mentioned People
Here is an example of the most mentioned people from 1000 Reddit posts from r/ArtificialInteligence.
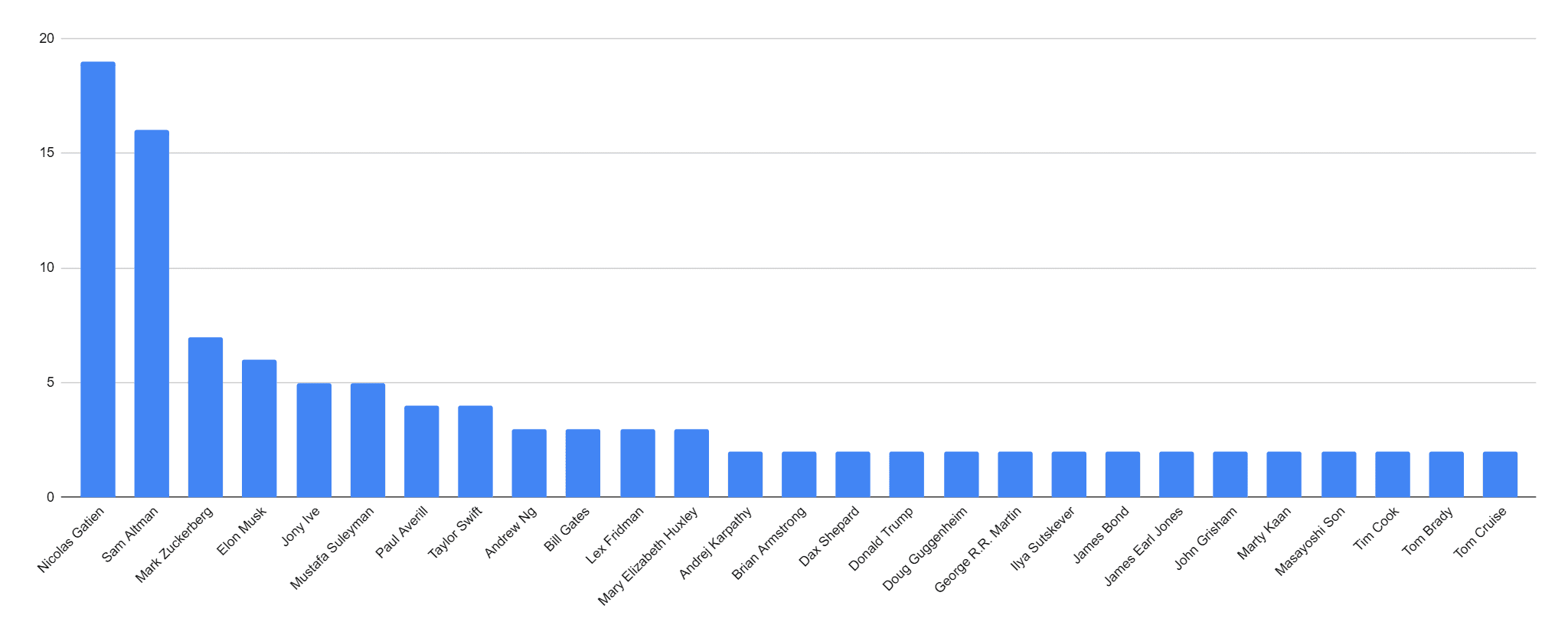
Having Sam Altman, Mark Zuckerberg and Elon Musk in the top 5 is not uncommon, but rather surprisingly the number 1 mention is Nicolas Gatien. Taylor Swift even made it in there at number 8.
Most Mentioned Software
Here is an example of the most mentioned software products from 1000 Reddit posts from r/ArtificialInteligence.
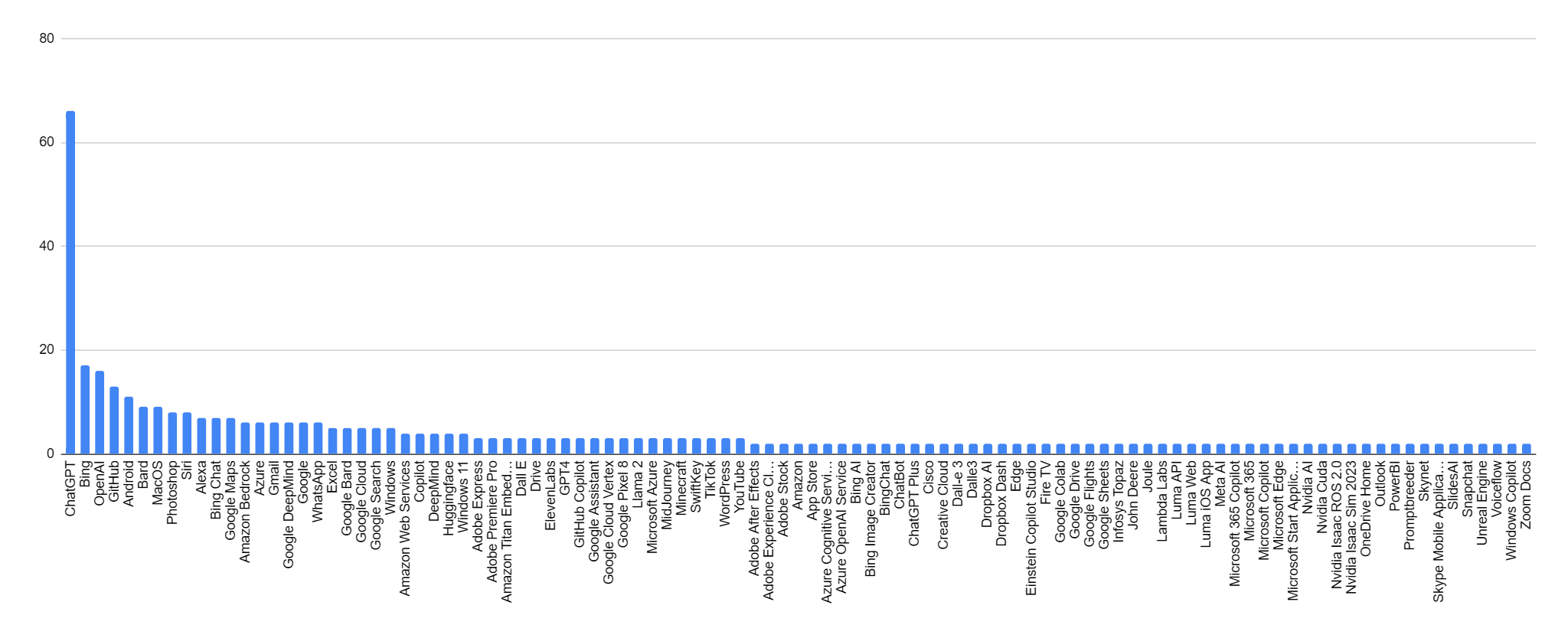
ChatGPT had 66 mentions, and OpenAI had 16 mentioned, but somewhat surprising was that Bing had 17 mentions. Amazon Bedrock had only 6 mentions, and AWS had 4.
Walkthrough
Let's walkthrough how to build this ourselves with Graphlit, with just a few API calls, and no AI experience required.
Ingesting the Reddit posts and analyzing them with Azure AI, can be completely automated with the Graphlit Platform.
We will be using the GraphQL API for the code samples, which can be called from any programming language, such as Python or Javascript.
Completing this tutorial requires a Graphlit account, and if you don't have a Graphlit account already, you can signup here for our free tier. The GraphQL API requires JWT authentication, and the creation of a Graphlit project.
Ingestion Workflow
First, we need to ingest the Reddit posts into Graphlit. This is done by creating a Reddit feed, along with a content workflow. The workflow object describes how the content will be ingested, prepared, extracted and enriched into the Graphlit knowledge graph.
Here we show how to create a workflow object with a createWorkflow GraphQL mutation, by specifying the use of Azure AI Language for extracting entities, i.e. people, organizations and labels (aka topics).
More information on configuring the extraction stage of the Graphlit workflow can be found here.
By assigning confidenceThreshold to 0.8, we are saying, only accept observed entities that we are 80% or more confident about.
// Mutation:
mutation CreateWorkflow($workflow: WorkflowInput!) {
createWorkflow(workflow: $workflow) {
id
name
state
extraction {
jobs {
connector {
type
azureText {
confidenceThreshold
}
}
}
}
}
}
// Variables:
{
"workflow": {
"extraction": {
"jobs": [
{
"connector": {
"type": "AZURE_COGNITIVE_SERVICES_TEXT",
"azureText": {
"confidenceThreshold": 0.8
}
}
}
]
},
"name": "Reddit Workflow"
}
}
// Response:
{
"extraction": {
"jobs": [
{
"connector": {
"type": "AZURE_COGNITIVE_SERVICES_TEXT",
"azureText": {
"confidenceThreshold": 0.8
}
}
}
]
},
"id": "35f8fab8-a787-418d-87f2-36b333d47660",
"name": "Reddit Workflow",
"state": "ENABLED"
}
Reddit Feed
Now that we have our content workflow defined, we can create our Reddit feed. Feeds automatically connect to the data source, such as Reddit, and read individual items, which are then ingested into Graphlit as content objects. Feeds can be scheduled to run once (which is the default) or on a scheduled basis, say every day.
In this case, we are assigning the GraphQL type of REDDIT, and the subredditName of ArtificialInteligence. We are asking for the most recent 1000 Reddit posts, by assigning readLimit of 1000.
And then we are assigning the workflow.idproperty to the workflow object we created above.
Once a successful response from the createFeed mutation has been received, data will start to be ingested automatically by the Graphlit Platform. Graphlit will process the Reddit posts in parallel, and scale out automatically to increase throughput.
NOTE: You can check on the status of the feed via the feed query, and see what data has been ingested via the contents query.
// Mutation:
mutation CreateFeed($feed: FeedInput!) {
createFeed(feed: $feed) {
id
name
state
type
}
}
// Variables:
{
"feed": {
"type": "REDDIT",
"reddit": {
"subredditName": "ArtificialInteligence",
"readLimit": 1000
},
"workflow": {
"id": "35f8fab8-a787-418d-87f2-36b333d47660"
},
"name": "Reddit Feed"
}
}
// Response:
{
"type": "REDDIT",
"id": "04ab5e05-b174-4f8b-829d-0edd782afca3",
"name": "Reddit Feed",
"state": "ENABLED"
}
Faceted Query
Ingesting all 1000 posts, and running Azure AI to extract all the entities, will take a few minutes.
When all content has been ingested, you can analyze the observed entities that Azure AI found in the Reddit posts.
Here we are creating a faceted query of all contents. You'll notice we're assigning the limit to 0, which means, only return the facets, not the contents themselves. We are asking for the facet type of OBSERVABLE, which means any observed entity, such as person, organization or label.
The results will contain a JSON array of unique observed entities, and their counts. We are showing just the first result here, with the label of AI which was seen 595 times across 1000 Reddit posts. (You will receive the top 1000 observed entities in the result set.)
// Query:
query QueryContents($filter: ContentFilter!, $facets: [ContentFacetInput]) {
contents(filter: $filter, facets: $facets) {
facets {
facet
count
type
observable {
type
observable {
id
name
}
}
}
}
}
// Variables:
{
"filter": {
"limit": 0
},
"facets": [
{
"facet": "OBSERVABLE"
}
]
}
{
"facets": [
{
"facet": "OBSERVABLE",
"observable": {
"type": "LABEL",
"observable": {
"name": "AI",
"id": "aeb768b0-7fa1-4037-b452-2f4060d3a82c"
}
},
"type": "OBJECT",
"count": 595
},
// ...
]
}
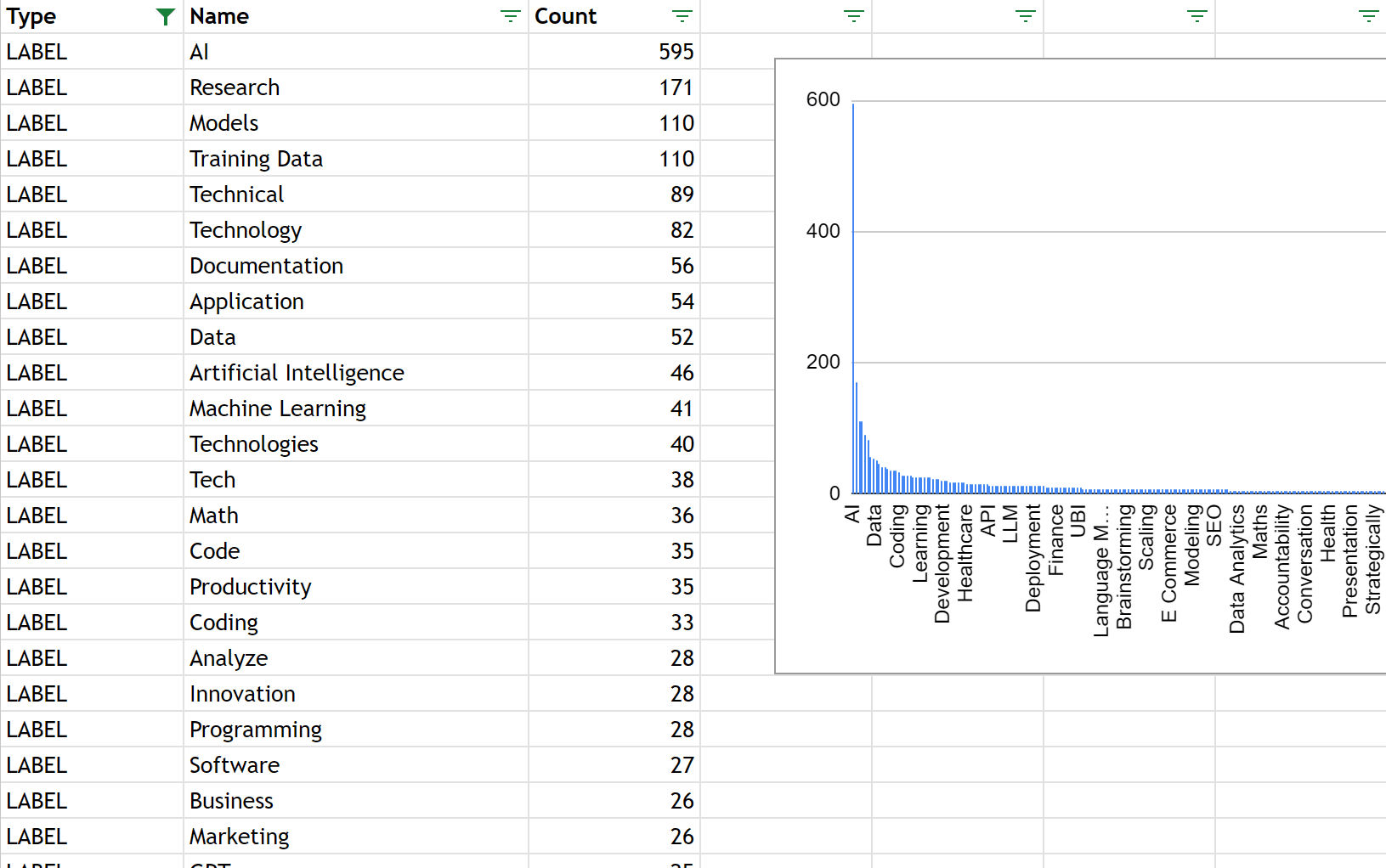
Faceted Data
Now that we have the faceted data in JSON format, it's interesting to read, but hard to visualize what has been mentioned most often.
We can import the faceted data into Google Sheets, after conversion to CSV, to make it easier to visualize the observed people, organizations and labels. This data could be imported into any spreadsheet or business intelligence tool, as well.
(See the bottom of this tutorial for a Python script which can be used to convert the faceted data from JSON format into CSV, for easier import into a spreadsheet.)
Structured Results
As you can see, Graphlit is a powerful tool for automated data ingestion, analysis via AI, and extracting structured data from unstructured data sources.

Next Time
In our next tutorial, we will show how to leverage this extracted data by using Large Language Models (LLMs) to ask questions, summarize and repurpose this Reddit market intelligence data.
Please email any questions on this tutorial or the Graphlit Platform to questions@graphlit.com.
For more information, you can read our Graphlit Documentation, visit our marketing site, or join our Discord community.
Appendix: JSON-to-CSV Conversion
The data imported into Google Sheets was in this CSV format:
Type,Name,ID,Count
LABEL,AI,aeb768b0-7fa1-4037-b452-2f4060d3a82c,595
And here is a Python script to convert the GraphQL JSON output into this CSV format.
import json
import csv
# Function to extract data and write to CSV
def json_to_csv(input_json_file, output_csv_file):
with open(input_json_file, 'r') as json_file:
data = json.load(json_file)
# Extract data from JSON
facets = data.get("facets", [])
csv_data = []
for facet in facets:
observable = facet.get("observable", {})
type = observable.get("type", "")
observable_name = observable.get("observable", {}).get("name", "")
observable_id = observable.get("observable", {}).get("id", "")
count = facet.get("count", 0)
csv_data.append([type, observable_name, observable_id, count])
# Write data to CSV file
with open(output_csv_file, "w", newline="") as csv_file:
csv_writer = csv.writer(csv_file)
csv_writer.writerow(["Type", "Name", "ID", "Count"])
csv_writer.writerows(csv_data)
print(f"CSV data written to {output_csv_file}")
# Specify the input JSON file and output CSV file
input_json_file = r"observables.json"
output_csv_file = r"observables.csv"
# Call the function to convert JSON to CSV
json_to_csv(input_json_file, output_csv_file)