
Model-Agnostic Text Summarization
For long-format content, like an ArXiV research paper, Large Language Models (LLMs) can expedite your learning by summarizing multiple pages of a PDF into bite-size paragraphs.
In this case, we want to summarize this excellent paper on the unification of LLMs and knowledge graphs.

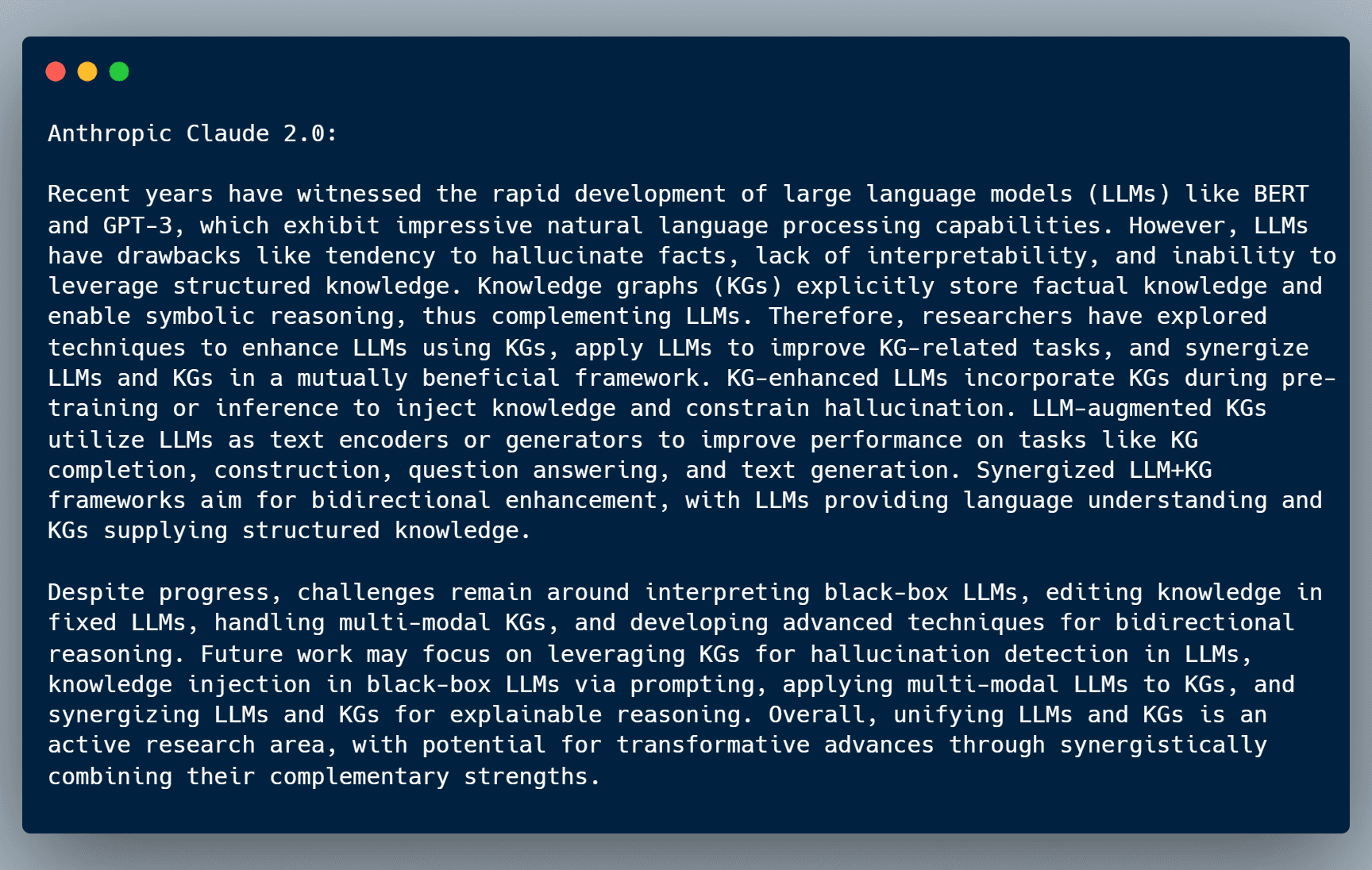
Anthropic Claude 2.1
With Anthropic releasing their new Claude 2.1 LLM recently, let's see how it does for summarizing this paper.

Compared to their previous Claude 2.0 model, the results look very good for such a short summary.
Walkthrough
Let's see how to use Graphlit to summarize this ArXiV PDF.
With Graphlit's model-agnostic approach, we can use the same content workflow to ingest the PDF, using different LLMs for summarization.
We will be using the GraphQL API for the code samples, which can be called from any programming language, such as Python or Javascript.
Completing this tutorial requires a Graphlit account, and if you don't have a Graphlit account already, you can signup here for our free tier. The GraphQL API requires JWT authentication, and the creation of a Graphlit project.
LLM Specification
First, we need to create a specification, which defines which LLM to use for summarization. Think of this as a 'preset' which specifies that we're using the CLAUDE_2_1 model, with a temperature of 0.1 and top_p (aka probablility) of 0.2. We are asking for a maximum of 512 tokens in the summary response.
// Mutation:
mutation CreateSpecification($specification: SpecificationInput!) {
createSpecification(specification: $specification) {
id
}
}
// Variables:
{
"specification": {
"type": "COMPLETION",
"serviceType": "ANTHROPIC",
"anthropic": {
"model": "CLAUDE_2_1",
"temperature": 0.1,
"probability": 0.2,
"completionTokenLimit": 512
},
"name": "Anthropic Claude 2.1"
}
}
Content Workflow
Next, we create a workflow, which uses this specification for summarization.
Here we are asking for 2 paragraph summary, with a total of 512 tokens, and assigning the Claude 2.1 specification.
This workflow only needs to be created once, and can be reused, as you ingest any form of content to be summarized.
Any content type can be summarized: web pages, PDFs, Notion pages, Slack messages, or even audio transcripts.
// Mutation:
mutation CreateWorkflow($workflow: WorkflowInput!) {
createWorkflow(workflow: $workflow) {
id
}
}
// Variables:
{
"workflow": {
"preparation": {
"specification": {
"id": "d9bf3f23-1b0d-4a46-ad27-81250d64b4f7"
},
"summarizations": [
{
"type": "PARAGRAPH",
"tokens": 512,
"items": 2
}
]
},
"name": "Anthropic Summarization"
}
}
Ingest PDF
Now we can ingest the ArXiV PDF, simply by assigning this Anthropic Summarization workflow.
Graphlit will extract all pages of text from the PDF, and then use recursive summarization to generate the two paragraphs of summary. Graphlit adapts to the context window of the selected model, and since Claude 2.1 supports 200K tokens, the summarization can be done in one pass for long PDFs.
// Mutation:
mutation IngestFile($name: String, $uri: URL!, $workflow: EntityReferenceInput) {
ingestFile(name: $name, uri: $uri, workflow: $workflow) {
id
}
}
// Variables:
{
"uri": "https://arxiv.org/pdf/2306.08302.pdf",
"workflow": {
"id": "52bc5aee-35b1-4772-b3f7-b5060cd445aa"
}
}
Get Content
The PDF will be ingested asynchronously, and you can poll the content by ID, and check for completion. (Alternately, Graphlit supports webhook actions, where you can be notified on every content state change.)
When the state field is FINISHED, the content workflow has completed, and the summary field has been populated.
// Query:
query GetContent($id: ID!) {
content(id: $id) {
id
summary
state
}
}
// Variables:
{
"id": "5ca3e036-7ecd-4b72-b72f-1918a4fe09a3"
}
// Response:
{
"summary": "Large language models (LLMs) and knowledge graphs (KGs) are two major technologies in AI that have complementary strengths and limitations. LLMs excel at understanding natural language and generalizing to new data, but lack structured knowledge and reasoning capabilities. In contrast, KGs explicitly represent factual knowledge and support symbolic reasoning, but have limited coverage and language understanding. To address these limitations, researchers have proposed various methods to enhance LLMs using KGs, apply LLMs to improve KG-related tasks, and synergize LLMs and KGs in an integrated system. Key techniques include injecting KGs into LLM pre-training or inference, using LLMs for KG completion and construction, jointly encoding text and KGs, and fusing LLM and KG representations for reasoning. However, challenges remain in scaling knowledge injection, avoiding knowledge hallucination, editing LLM knowledge, handling multi-modal KGs, and enabling bidirectional reasoning over data and knowledge.\n\nThere are several promising future directions in unifying LLMs and KGs. This includes using KGs for detecting and assessing hallucination risks in LLMs, editing knowledge in black-box LLMs via prompts, developing multi-modal LLMs to process image and video KGs, and improving understanding of KG structure and reasoning patterns. Additionally, tighter integration and synergy of LLMs and KGs could lead to more capable and trustworthy systems, powered by both data-driven and knowledge-driven inferences. Such systems hold promise for diverse real-world applications like search engines, recommender systems, and AI assistants.",
"id": "5ca3e036-7ecd-4b72-b72f-1918a4fe09a3",
"state": "FINISHED"
}
LLM Summarization Comparison
Again, here is what Claude 2.1 has returned for the summary:
By changing the specification to use the Azure OpenAI GPT-3.5 16K model, we get the summary:

Or, by changing the specification to use the Azure OpenAI GPT-4 model, we get the summary:

We can even use the newly released OpenAI GPT-4 Turbo 128K model, and get this summary:

Change the Specification LLM
To use different models with your specification, you will need to assign the serviceType as AZURE_OPEN_AI, OPEN_AI or ANTHROPIC. Then, you can fill in the model-specific fields such as azureOpenAI.model, as shown here.
Specifications can be updated in-place, without needing to change your workflow.
// Mutation:
mutation UpdateSpecification($specification: SpecificationUpdateInput!) {
updateSpecification(specification: $specification) {
id
name
state
type
serviceType
}
}
// Variables:
{
"specification": {
"serviceType": "AZURE_OPEN_AI",
"searchType": "VECTOR",
"azureOpenAI": {
"model": "GPT35_TURBO_16K",
"temperature": 0.1,
"probability": 0.2,
"completionTokenLimit": 512
}
"id": "d9bf3f23-1b0d-4a46-ad27-81250d64b4f7"
}
}
Summary
Graphlit provides a model-agnostic approach to using LLMs for text summarization, and simplies the integration of new models like Anthropic Claude 2.1 in your knowledge-driven applications.
We look forward to hearing how you make use of Graphlit in your applications.
If you have any questions, please reach out to us here.