
With the release of the JFK Files, it provided a robust set of real-world examples of scanned and handwritten PDFs.
Given the variety of API services, as well as visual LLMs, for PDF to Markdown extraction, here we will compare the output from an example PDF.
This PDF is three pages long, and appears to be a scanned classified message form.

For each output example below, we have copy/pasted the output Markdown into Markdown Live Preview and taken a screenshot of the formatted Markdown.
Using Graphlit
Azure AI Document Intelligence: Layout Model

Azure AI Document Intelligence: Read/OCR Model

Anthropic Claude Sonnet 3.5
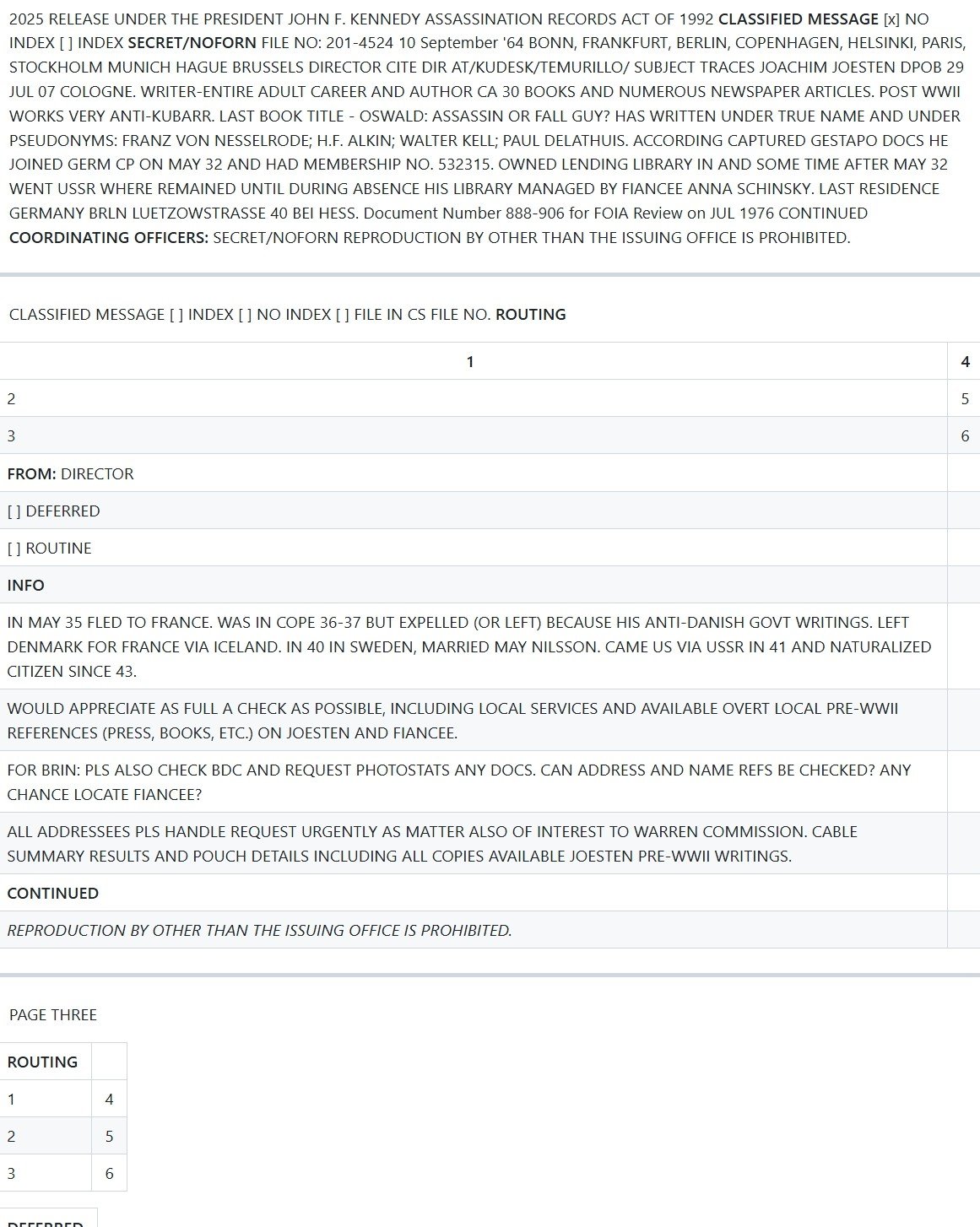
Anthropic Claude Sonnet 3.7
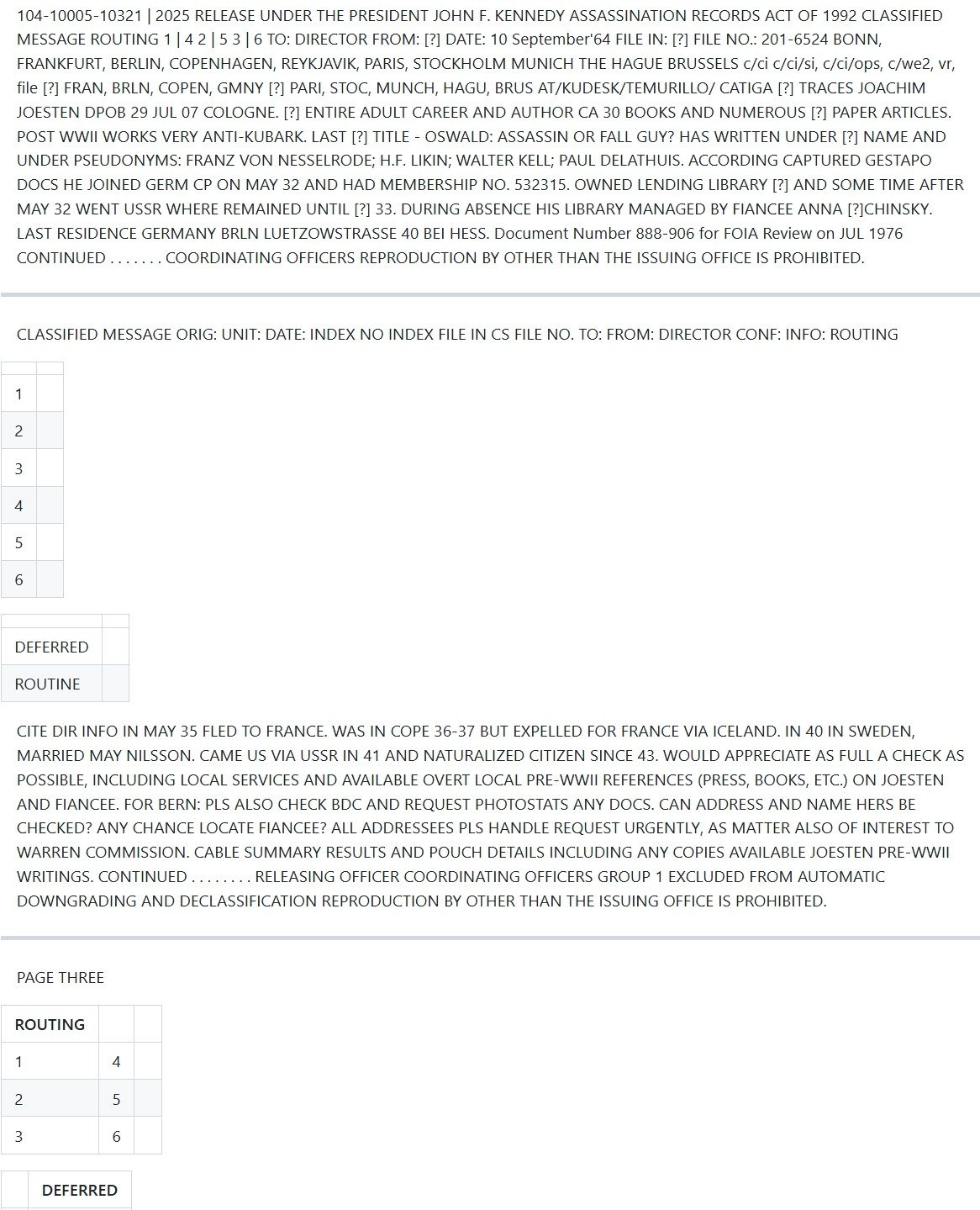
Anthropic Claude Sonnet 3.7 (w/ Thinking enabled)
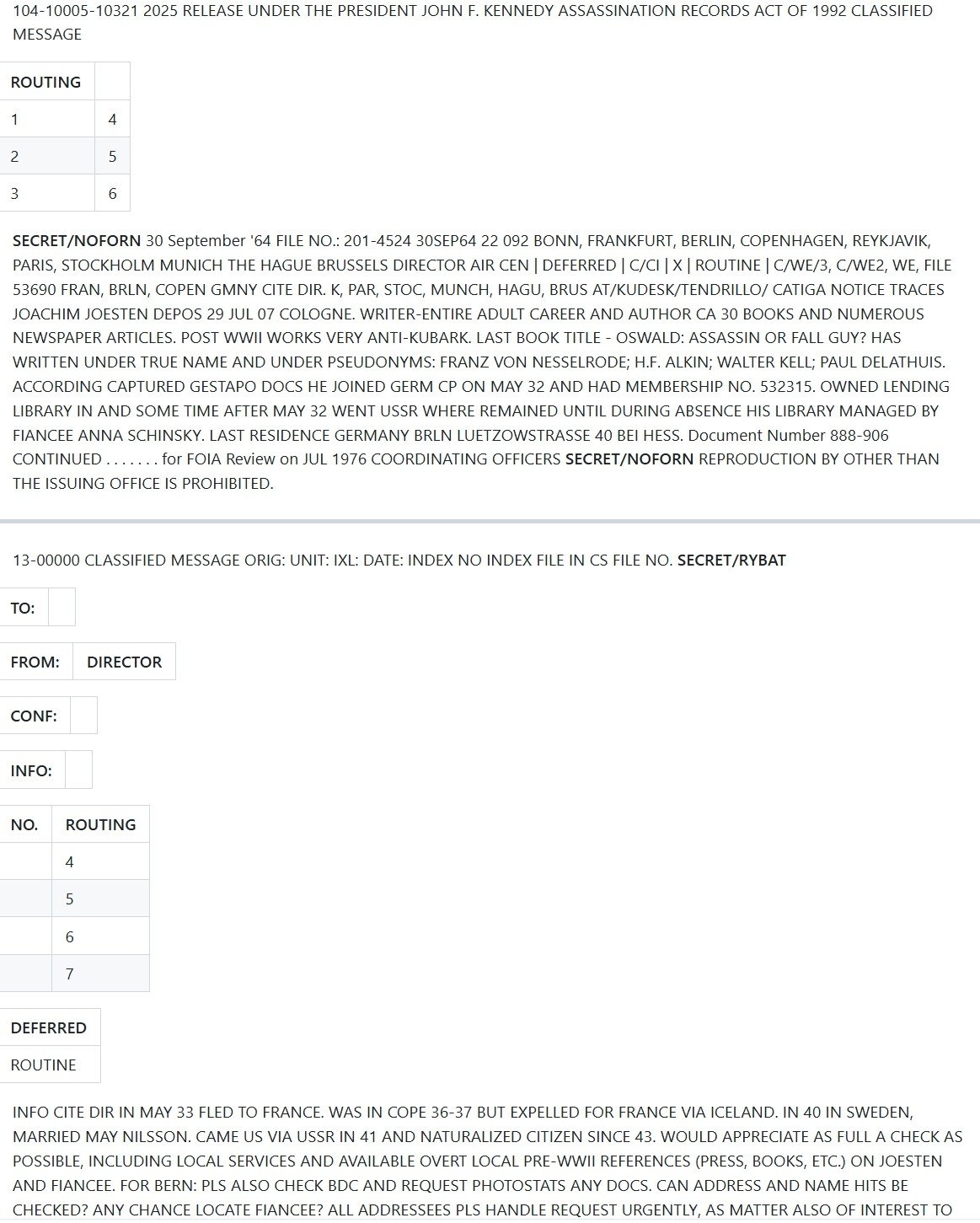
OpenAI GPT-4o

Gemini 2.0 Flash

Gemini 2.0 Pro
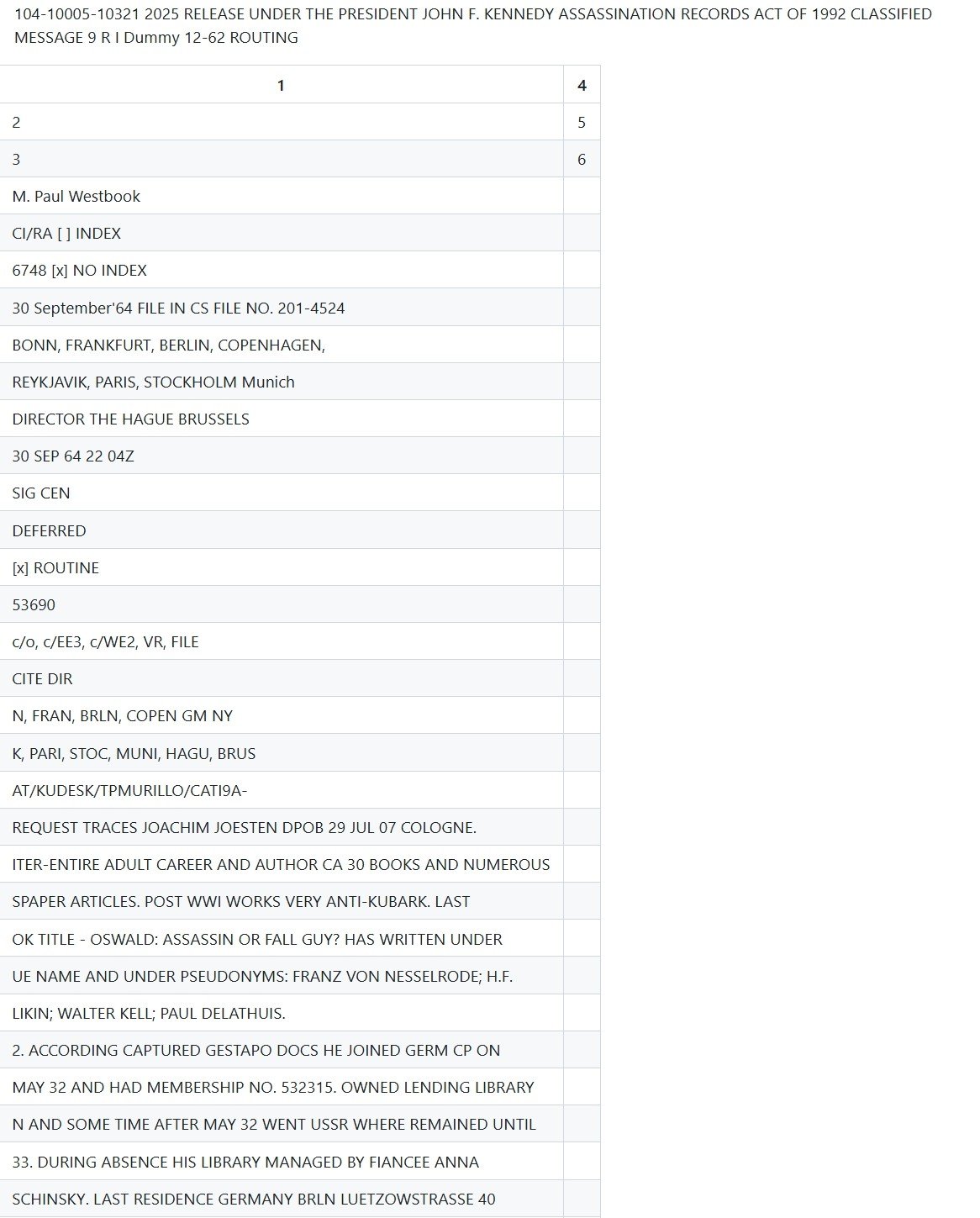
Mistral OCR

Using other APIs
Chunkr

Reducto

Reducto (Agentic mode)

LlamaCloud (Premium mode)

LLMWhisperer

Summary
This comparison shows the diversity of PDF extraction results, across available APIs and visual LLMs.
You will need to evaluate the proper solution based on the layout and type of content that you are starting with.
Also, for each of these results, they come with a difference in cost per page, depending on the compute required.
Please email any questions on this article or the Graphlit Platform to questions@graphlit.com.
For more information, you can read our Graphlit Documentation, visit our marketing site, or join our Discord community.