


















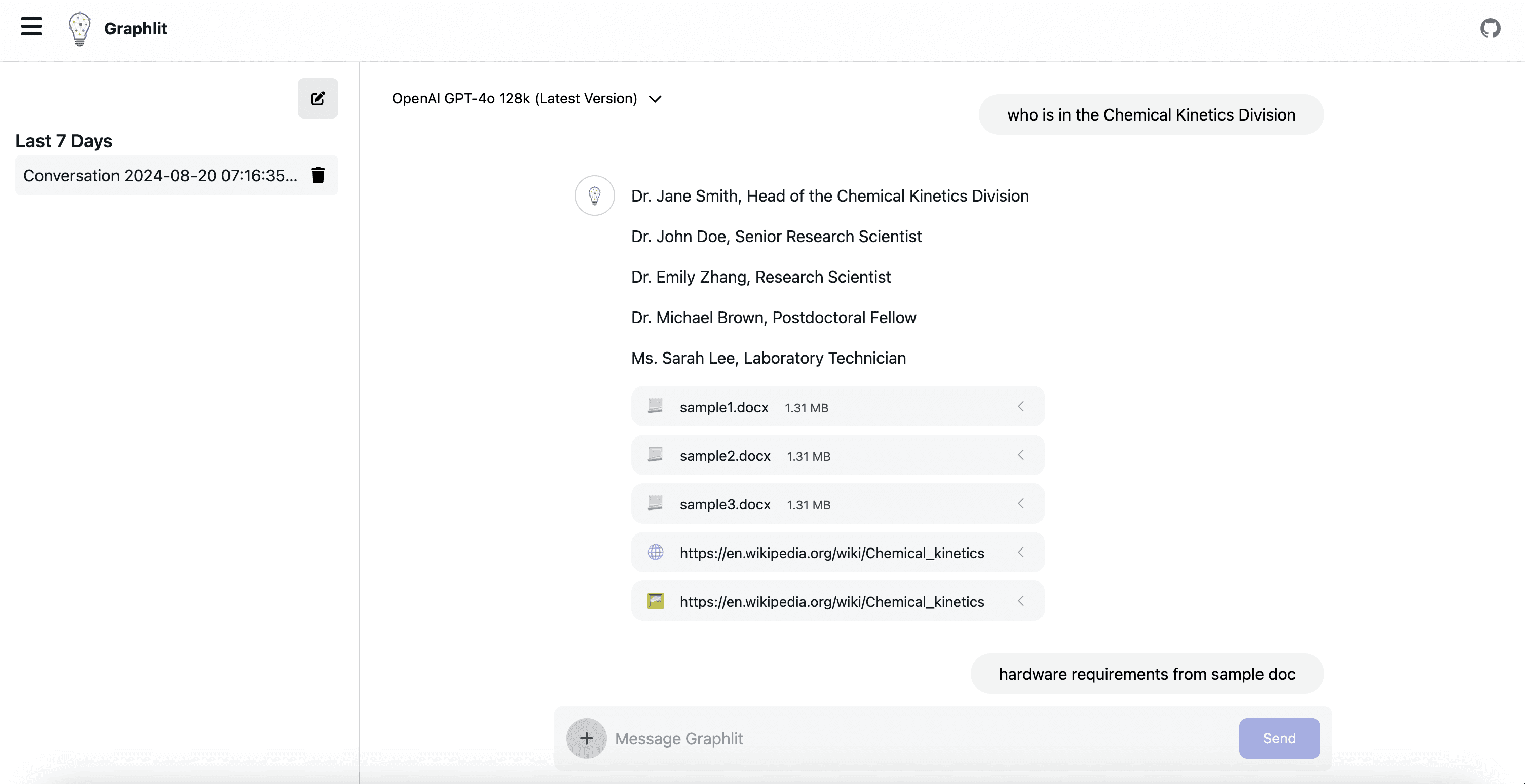
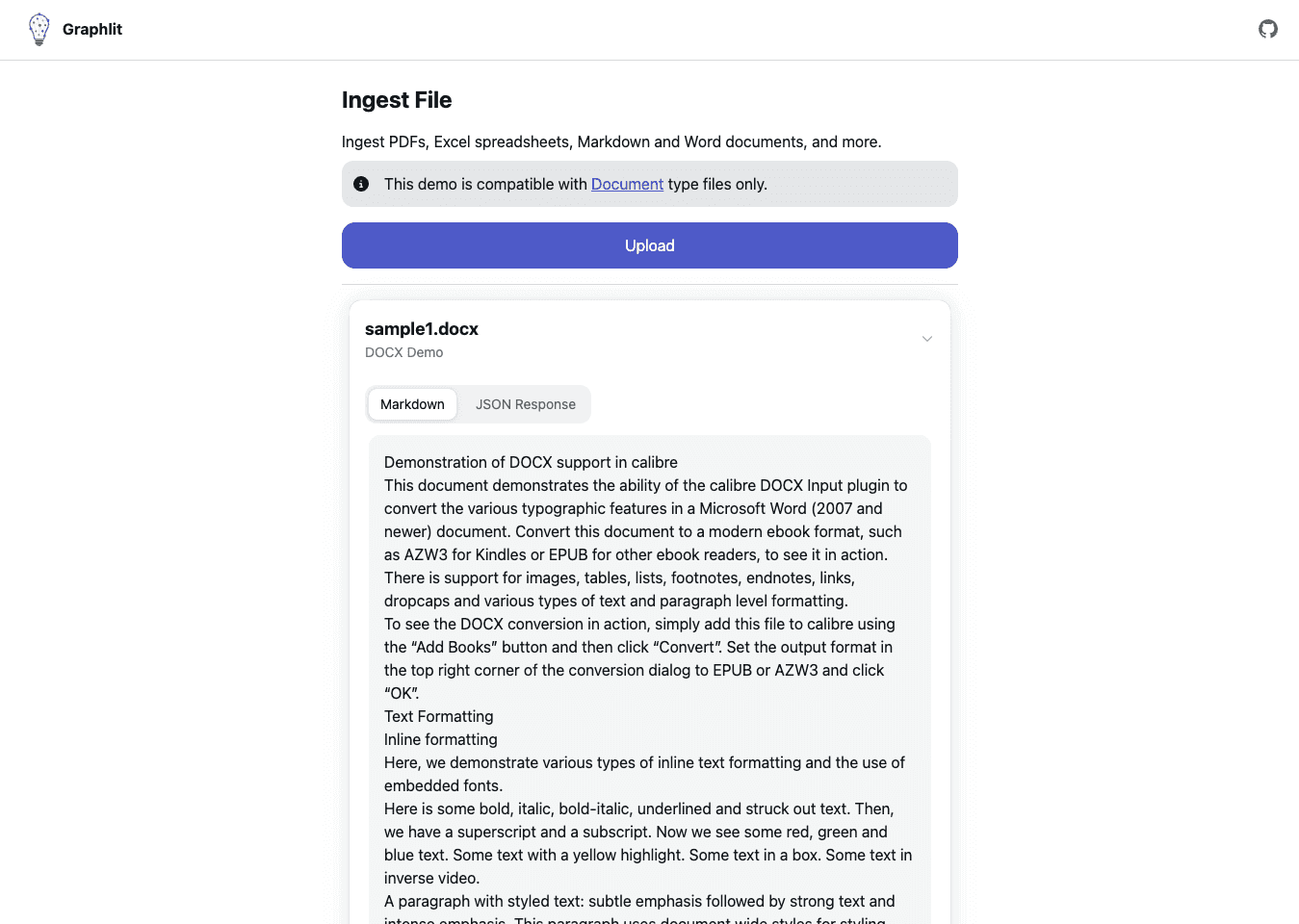
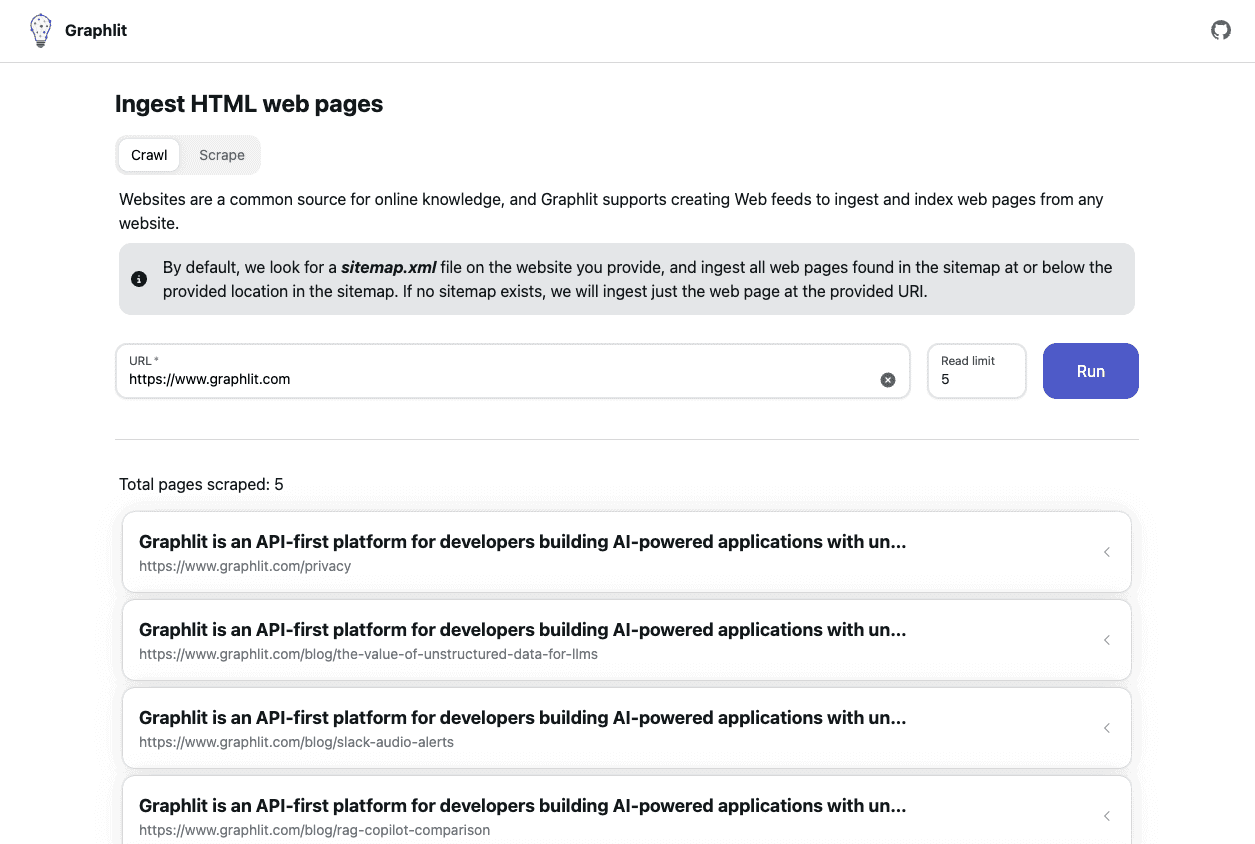
What can I ingest?
Ingest from any data source such as:
Web sites, cloud storage, SharePoint, podcasts,
Jira, Notion, YouTube, email or Slack
Ingest any unstructured data format such as:
documents, HTML, Markdown, audio, video, or images
Data feeds for automated ingestion
Extract text and tables from documents and images with OCR and LLMs
Automatic audio transcription with Deepgram
Automated web scraping
Enrich data with external APIs, such as Wikipedia and Crunchbase
RAG and GraphRAG Ready: Intelligent text extraction and chunking, built-in vector embeddings and conversation history, LLM-based entity extraction
Semantic Search: Vector-based search, including metadata filtering
Content Creation: Automated text and transcript summarization, social media post generation, long-form content creation
Integrated with Large Multimodal Models (LMMs) including OpenAI
GPT-4o and Anthropic Sonnet 3.5Generate image descriptions with visual object detection
Similarity search via image embeddings
Native SDKs for Python, Node.js, .NET
No infrastructure to be deployed
Integrated usage logs
Serverless, cloud-native platform
Multitenant-ready with RBAC
Data is encrypted-at-rest
Usage-based pricing
Pricing
How much does Graphlit cost?
Free to get started, no credit card required.
Usage-based pricing starts at $0.10/credit
Content cost
Free
$0
per/month
Ingest any content type
(i.e. PDFs, MP3s, web pages)
Create content feeds
(i.e. RSS, Web, Notion, blob storage)
Search content by
text or vector similarity
Filter content by metadata
Create chatbot conversations
over your content
Configure content workflows
Includes Deepgram audio transcription
Includes all vector embeddings
and prompt completions
Supports multi-tenant apps
Includes 100 credits
Up to 1GB content storage
Up to 1000 content items
Up to 3 feeds
Up to 100 chatbot conversations
Community Discord support
Hobby
$49
/month + usage
Everything in Free tier
$0.10/credit usage
Up to 10GB content storage
Up to 10K content items
Unlimited feeds
Unlimited chatbot conversations
Email and community Discord support
Starter
$199
/month + usage
Everything in Hobby tier
$0.09/credit usage (10% off)
Up to 100GB content storage
Unlimited content items
Unlimited feeds
Unlimited chatbot conversations
Priority email, private Slack support
Growth
$999
/month + usage
Everything in Starter tier
$0.08/credit usage (20% off)
Unlimited content storage
Unlimited content items
Unlimited feeds
Unlimited chatbot conversations
Priority email, private Slack support
Dedicated technical contact
SLA (coming soon)
SOC 2 (coming soon)